

Testing GenAI on Marine Corps Doctrine
Is My AI a Warfighting Scholar?

Bottom Line Up Front:
The Department of Defense must develop robust and task-specific tests to enable effective GenAI integration.
Not all GenAI models understand military doctrine equally. GenAI performance gaps should be identified and addressed before consideration for defense applications.
This article introduces MarineBench, a tailored benchmark for tasks related to Marine Corps doctrine. Such benchmarks will enable the DoD to make more informed development and investment decisions in AI.
Industry is only beginning to scratch the surface of the potential of generative artificial intelligence (GenAI), and the Department of Defense (DoD) is by its nature several steps behind. Industry's ability to harness GenAI is predicated on domain-specific performance, where performance gains can come from the inclusion of tailor-made models or highly scoped and relevant data in model training methodologies. To make the most effective use of GenAI, the DoD must understand the military domain-specific performance of the models it deploys. This article introduces the concept of benchmarks to assess GenAI model performance, discusses the use of GovBench as an existing solution for DoD-specific domain performance testing, and introduces a novel benchmark, MarineBench, as a proof of concept for Marine Corps-specific domain knowledge.
Benchmarking
By using domain or task-specific tests called benchmarks, we can quantitatively evaluate the domain-specific performance of models like OpenAI’s o3 or DeepSeek’s R1. Standard industry benchmarks typically consist of generalized tasks or knowledge domains such as math, coding, and reasoning. Benchmarks like the one proposed by GovBench have also initiated an important national security community discussion about GenAI testing. As the Department of Defense accelerates AI adoption for warfighting and enterprise processes, responsible AI testing must become standard practice.

Hallucinations and knowledge gaps have defined GenAI since ChatGPT popularized the technology. Despite exhibiting conversational capabilities that resemble interactions with another human, these models do not actually know anything. They generate text by predicting likely word sequences based on patterns in their training data. As an example, if someone says “peanut butter” while discussing sandwiches you would reasonably assume the next words will be “and jelly.” When data is missing or sparse, knowledge gaps emerge. Hallucinations occur when a model confidently produces false or nonsensical information, and such errors remain a persistent issue even in newer models. Returning to the sandwich example, a hallucination might entail the model confidently responding to the prompt, “peanut butter and ___ sandwiches” with “anchovies” or “light post.” While this example is amusing, other real-world hallucinations are far more concerning, such when a model cites fake studies or offers inaccurate medical advice. Benchmarks offer a consistent and reliable way to detect and evaluate these model failures before making models generally available.
GovBench
Consistent benchmarking provides the GenAI community with valuable guideposts to contextualize and quantify performance. GovBench is an open-source project that aims to establish the standard for evaluating GenAI models within government domains. The project recently tested leading GenAI models against their JointStaffBench test, consisting of 4610 questions covering the six major joint doctrine publications. The GovBench benchmarking questions include multiple-choice and free response questions on several Joint Force topics, ranging from personnel management to military communication systems. For example, a multiple choice intelligence question in the dataset asks, “Which principle for multinational intelligence sharing requires alignment with US policy on releasing classified information?” GovBench presents the question and multiple choice answers to the model and records the generated answer using AI Security Institute (AISI) tools, while answers to free-response questions are evaluated for accuracy and relevance by an AISI GenAI grader model. GovBench found that OpenAI’s o3 outperformed the other models in the test with an overall score of 89%.
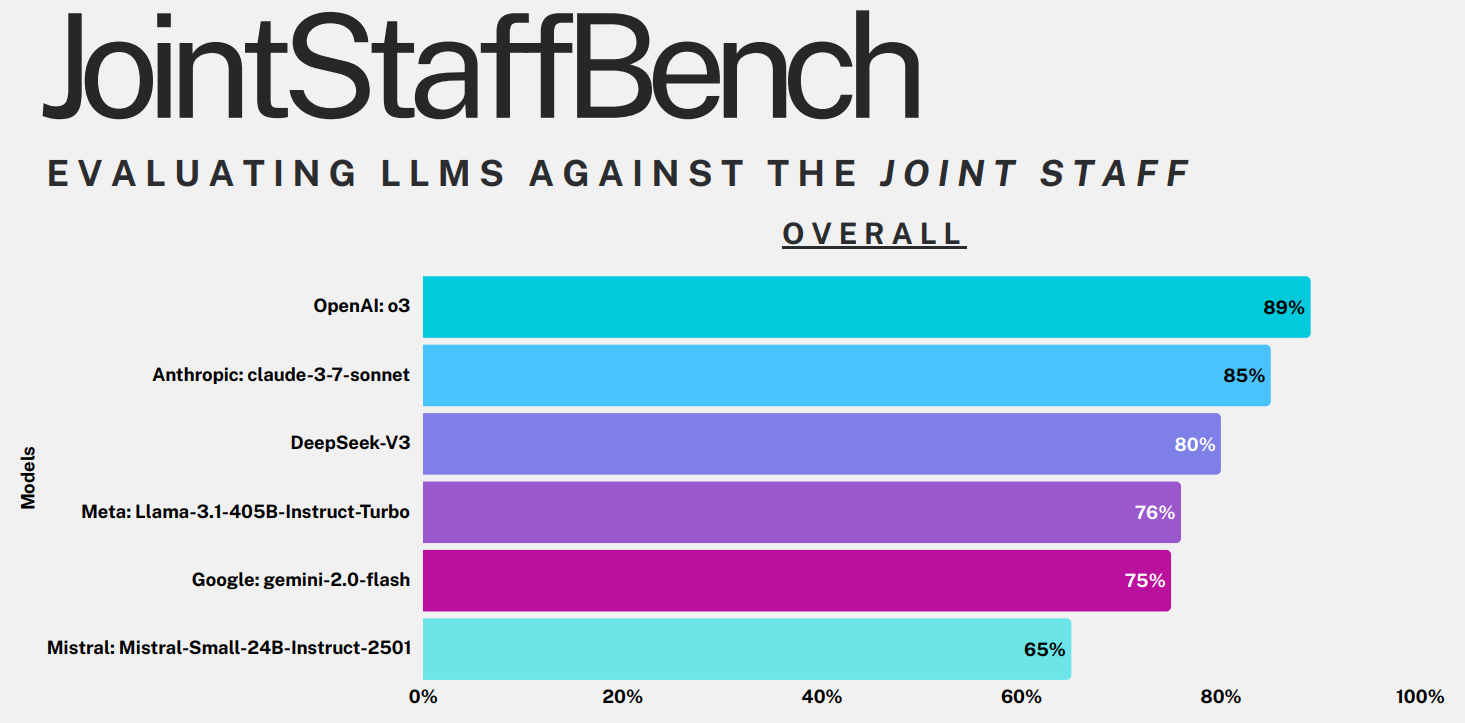
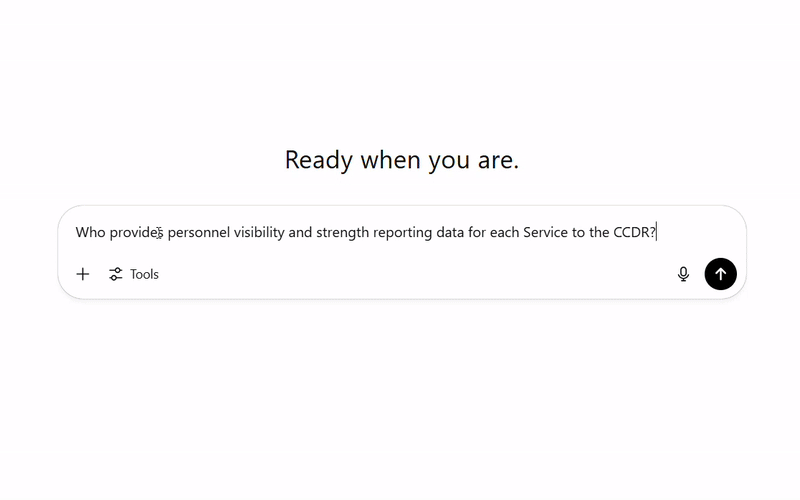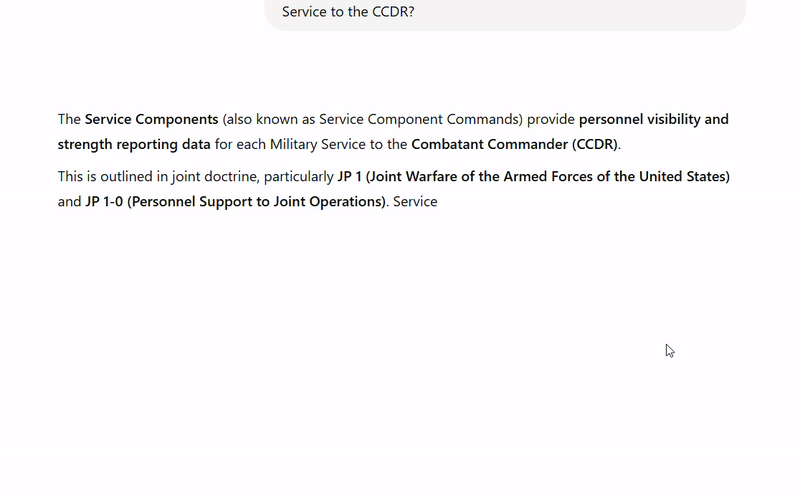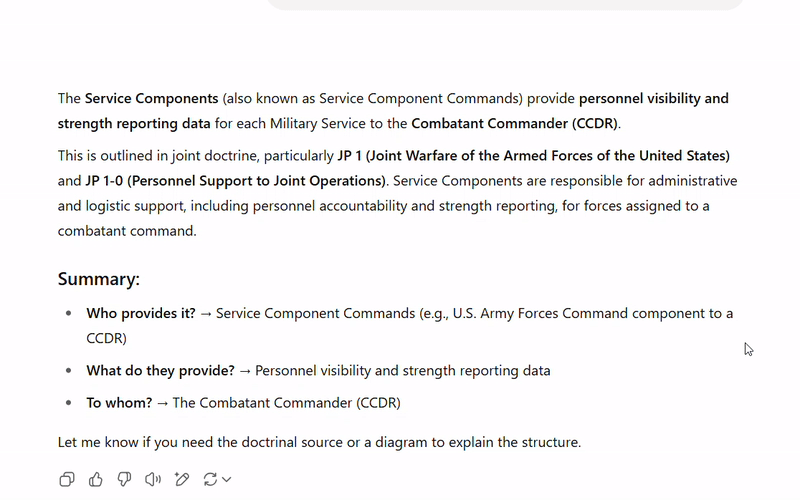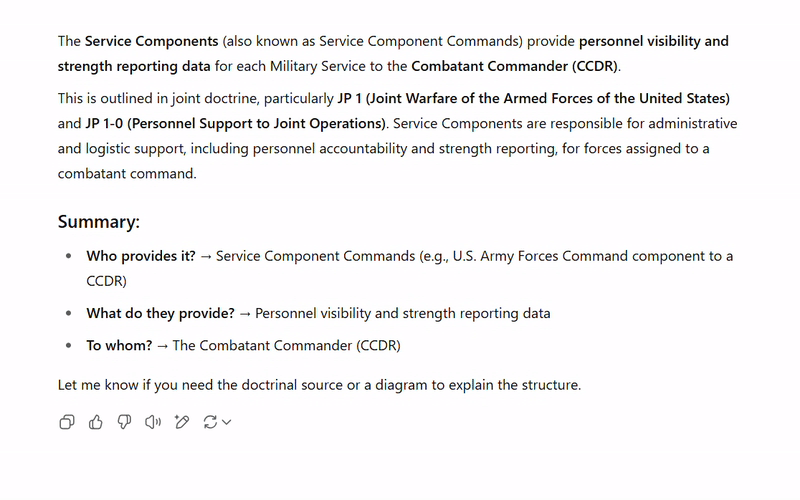
The JointStaffBench results show that large industry-leading models such as OpenAI’s o3 and Anthropic’s Claude 3.7 Sonnet outperform smaller models from DeepSeek, Meta, Google, and Mistral. Model size, as measured by the number of parameters, matters because larger models have a greater capacity to capture complex patterns and contextual nuances in language, enabling them to perform better on tasks requiring deep understanding or sophisticated reasoning. However, even the seemingly poor performance of Mistral-Small-24B (where 24B denotes the model’s 24 billion parameters) comprised ~3000 correct answers to multiple-choice and free-response questions. Although we don’t have access to GovBench’s results, it is reasonable to speculate that the small model’s performance likely suffered on the 700 free-response questions. 100B+ models like o3 and Claude 3.7 Sonnet perform better on writing tasks as a result of their large training data sets. For example, in the head-to-head comparison between OpenAI’s o4 and the much smaller Llama 3.1-8B model shown below, OpenAI’s o4 model generates a more concise and contextually appropriate answer.

Marine Corps Bench (MarineBench)
The Marine Corps Bench is motivated by the question, “How well do GenAI models know the Marine Corps?” The Marine Corps’ unique culture is anchored in service doctrine, embodied in a series of documents known as Marine Corps Doctrinal Publications (MCDPs). The MCDPs outline the organization’s guiding principles and strategies on topics ranging from warfighting to expeditionary operations. Similar in design to the JointStaff Bench, the MarineBench is composed of 725 multiple-choice questions and answers generated from each of the eight MCDPs. An example question generated from MCDP 3: Expeditionary Operations asks, “Which factor often restricts the application of military force more in military operations other than war?” corresponding to the answer options “A. Technological inferiority,” “B. Limited resources,” “C. Lack of training,” and (the correct answer) “D. Political Concerns.” For testing and dataset refinement purposes, the generated data also contains an answer explanation.
Model selection is just as important as sound benchmarking practices. Selection criteria generally include performance, pricing, compute resources, and security concerns. For instance, a model’s size determines the compute resources and memory required to run the model, and can also serve a proxy for the model’s performance. While larger models generally perform better than smaller models, performance on nuanced and domain-specific tasks can defy this general trend. Additionally, benchmarking smaller and cheaper models can identify cost efficient alternatives for GenAI systems. Given that a smaller model performs well enough for the AI application, an enterprise GenAI system generating 1 billion output tokens a month with Llama 3.1-8b ($0.08/million output tokens) saves ~$95,000.00 annually when compared to OpenAI o3 ($8.00/M output tokens).
A range of leading GenAI models and smaller, cheaper, and even locally run models were tested on the MarineBench. Leading models including OpenAI’s o3, Anthropic’s Claude 3.7 Sonnet, and Google’s Gemini 2.0 Flash showed comparable and slightly better performance when compared to JointStaffBench. The high correctness scores indicate that the models tested were knowledgeable on Marine Corps doctrine.
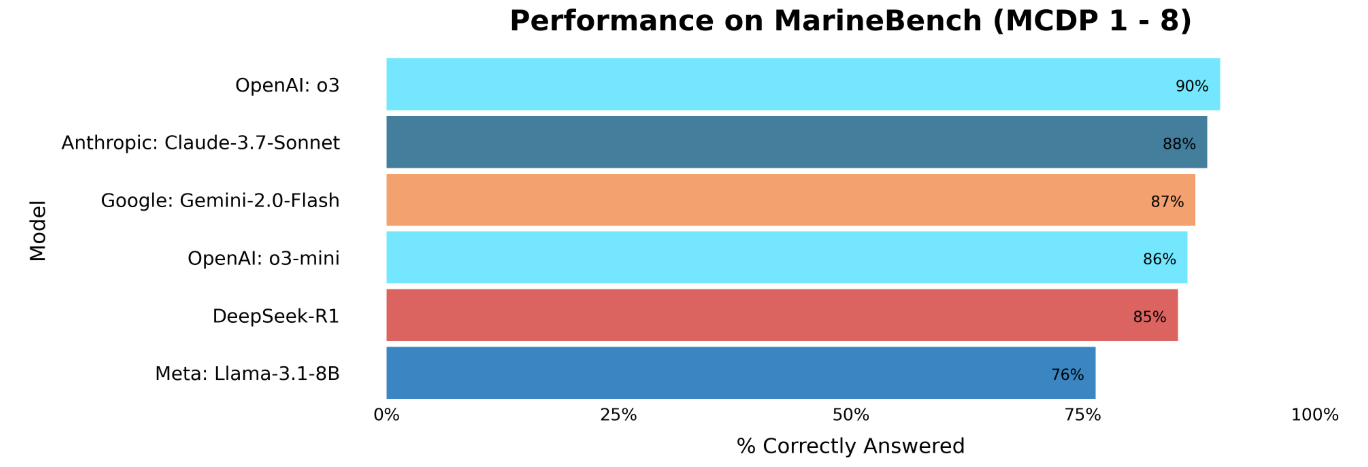
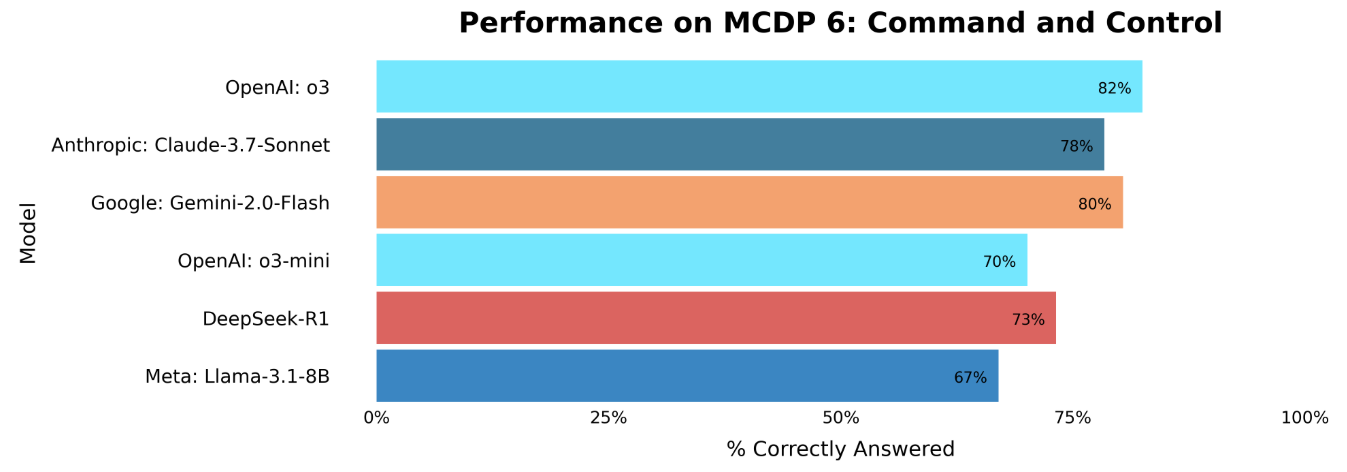
There are minimal observable performance differences between the five leading AI models on MarineBench, while JointStaffBench’s results, depicted in the first plot, show slightly more breakout among the same models. Without having the GovBench data to confirm, the higher variance in model performance on JointStaffBench likely owes to differences in each model’s free response answers. Assessing model failures is also an important part of benchmarking. On MarineBench, all models scored the lowest on MCDP 6: Command and Control. Low performance on benchmarks can indicate a model knowledge gap but can also be a result of poorly written benchmarks. In the MCDP 6 question set, there are instances of uncommon acronyms and fictional vignette references that appear to negatively impact model performance. All benchmarks, including the MarineBench, need to be iteratively improved and tailored for specific knowledge sets and use cases.
Conclusion
The DoD’s acceleration of AI integration into warfighting and enterprise processes demands tailored evaluation methods like MarineBench and JointStaffBench for quantifying model comprehension of military topics. Leading models have already shown their knowledge on Marine Corps doctrinal content, but future task-specific benchmarks will further test models’ ability to apply their domain-specific knowledge. Just as other military systems and units train rigorously before deployment, AI systems must undergo domain-specific testing before being trusted for defense applications. While MarineBench and JointStaffBench offer a rudimentary starting point for GenAI benchmarking, robust and task-specific tests must be developed to enable effective AI integration.
Read More of Our Work Here:
Do We Still See the Same Game Board? Schelling Points and Strategic Salience in an Age of Upheaval
The War Quants Counter UAS Primer: Introduction
From Hours to Seconds: Automating Naval Flight Schedules with Data Science
The views and opinions expressed on War Quants are those of the authors and do not necessarily reflect the official policy or position of the United States Government, the Department of Defense, or any other agency or organization.
This is exactly the kind of work that needs to happen before we start plugging GenAI into mission systems. Shows how dangerous it is to assume general performance equals military readiness. If a model fumbles MCDP 6, that’s not a bug, it’s a liability.
Also appreciate the nod to cost tradeoffs. There’s a place for smaller, cheaper models, but only if they’re tested where it counts. This is how we close the gap between Silicon Valley hype and actual warfighting utility.
Great one, I can imagine doing a lot with this idea. I saw deepseek does very well, makes me wonder if a local version could be safe enough to use.